
Throughput vs Latency
July 24, 2022
Latency is the time it takes for an action (initiated by a user or machine) to produce its intended effect (its response or output) in any given system. It's most often referenced in computer networking where it is the time it takes a request to complete its one-way or two-way (return) trip over a network. In the context of network requests, latency is typically measured in milliseconds on the low end, and in seconds on the high end. One request (and measure of latency) could be just a small part of a much bigger operation over many machines connected over a network (with a higher latency). For workloads that are not user-facing, an acceptable latency could be measured in minutes, hours, or longer.
The three keys to low latency are:
- Physically (or geographically) short trip from the source of the action to the destination of the data or computation.
- Minimal computation of any data during the request's trip (data should be pre-computed).
- Minimal time to find the data within its datastore (using good indexes on a database). This is technically also computation.
Throughput is the amount of data that is transferred per second. A trick to increase throughput of information without increasing throughput of data is to aggregate the data (i.e. combining values from multiple messages/records into one). If the data is a time series, then you lose resolution in this process (e.g. 60 separate 1-second records become a single 1-minute record).
Throughput is often measured in one of three ways:
- Requests per second (more data per request typically results in fewer requests per second).
- Messages or transactions per second (which could be batched per request).
- The amount of data per second (MB/s, GB/s, etc... more requests per second typically results in less data per second).
In this post, we'll explore 5 different architectures that satisfy different use cases for handling data under different requirements of latency and throughput. The architectures mentioned here are in the sphere of data pipelines within a datacenter. Architectures not mentioned are in the sphere of audio/video chat and gaming -- all of which could be handled via Peer-to-Peer communication. High frequency trading is another use case that's not mentioned here (where 1ms latencies are considered slow). The categorization of different throughput and latencies are roughly based on the following:
Throughput (records/messages per second):
High: >100,000 (this level of throughput is achieved with batching)
Medium: 10,000-100,000
Low: <10,000
Latency (sec):
High: >10
Medium: 1-10
Low: <1
Setting concrete thresholds of latency and throughput for each category (low, medium, high) is difficult because simple test benchmarks (like the ones linked throughout this post) are not perfectly representative of how the tools mentioned here are used in the real world. For example, Apache Kafka benchmarks often demonstrate latencies under 10ms, however, these benchmarks configure the tool being tested such that it will perform best for the given test. Each real-world use-case requires its own unique balance of configurations to provide the best trade-off of latency vs throughput for the given set of workloads. One use-case may yield a throughput that is vastly different from another. This isn't strictly a result of the configuration of the tools mentioned -- it's also a result of the vastly different system designs and workloads surrounding these tools.
Table of Contents
High Throughput and Medium-High Latency (large messages/files)
High throughput can be achieved many ways -- it's just a matter of building a pipe (or parallel pipes) wide enough with as few bottlenecks as possible. The required latency and size of messages/files for a use case can help narrow the right choices. Given a required latency of seconds to minutes or more with large messages/files of MegaBytes to GigaBytes or more, a distributed filesystem (like AWS S3) provides a very simple, but effective, intermediary stateful resource for processing data between machines.
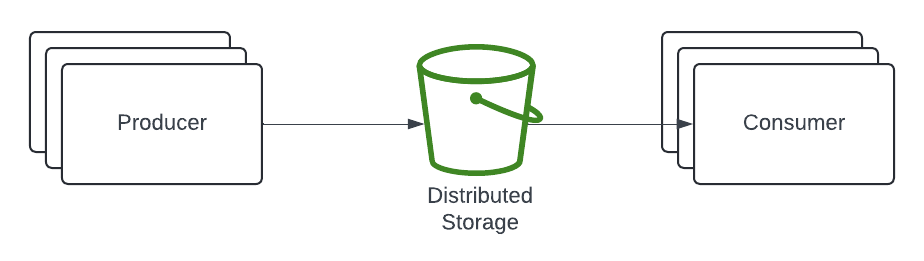
A wonderfully simple high-level design that becomes slightly more complex as the need arises for keeping track of which files were processed (not shown here).
Scaling
A cloud-managed object-store like AWS S3 handles these performance considerations for you. Scaling producer and consumer nodes depends on the use case and framework used for managing autoscaling.
High Throughput and Low-Medium Latency (small messages/files)
Asynchronous communication between services enables higher throughput with less chance of any one service waiting idle for a response. This is where message brokers like Apache Kafka and AWS Kinesis shine, providing an intermediary persistent storage that makes building a reliable, high-throughput, low-to-medium latency pipeline easier than direct communication between services. The emphasis is on reliable because having an intermediary persistent storage allows for a less-than-ideal state of consumers, producers, and dependant services to operate with less chance of connection issues, especially in a high-throughput use-case. In such less-than-ideal cases, latency can increase significantly.

Although this diagram is very simple at a high level, if you are using a message broker as capable as Apache Kafka or AWS Kinesis, then you most likely have a complex network of services surrounding them.
Scaling
Scaling consumer and producer nodes is as easy as the solution above using a distributed filesystem, however, depending on the chosen solution for message broker, scaling it may not be so easy. Scaling Kafka message brokers has traditionally been a manual undertaking, however, managed solutions do make it easier. AWS Kinesis provides auto-scaling with the help of additional components that require setting up.
Links:
- When not to use Apache Kafka
- Configure Kafka to minimize latency
- Best practices for consuming Amazon Kinesis data streams using Lambda
- AWS Kinesis Intro
Medium Throughput and Low-Medium Latency (small messages/files)
Apache Kafka and AWS Kinesis come with the management overhead of configuring of the message brokers or shards (respectively), as well as producer and consumer libraries. Kafka has much more configuration overhead than Kinesis, but can be tuned to be performant. Simpler solutions exist if throughput requirements aren't as high as 100,000 messages per second. RabbitMQ and Amazon SQS are message queues that are simpler solutions to the above powerhouses of asynchronous message streaming.
The high-level design is identical to that of the message brokers above, but the implementation and configuration is very different.
Scaling
Amazon SQS manages its own auto-scaling, while RabbitMQ requires configuration.
Links:
High Throughput and Low Latency
If you're building something with these requirements, then you're likely not this blog's intended audience!
Although Apache Kafka and AWS Kinesis are capable of fairly low latencies (including less than 1sec), they both add the overhead of an additional network hop and disk write/read which could be eliminated with direct synchronous communication between client and server. There's not a single (or set of designs) to satisfy the infinite use cases that require high throughput and low latency, however, below are some tools and designs that can help achieve the holy grail of high throughput and low latency:
- AWS Network Load Balancer
- Sharding datastores as well as their surrounding services with cell-based architecture
- Proper indexing of data to quickly find and retrieve search targets, such as the Q-Gram index used in Google Search
Low Throughput and Low Latency
This is the simplest problem to solve because data doesn't need to be distributed, and there aren't any networking or processing bottlenecks to worry about. Caching wouldn't need to be implemented if the throughput is low, but as throughput increases, it's the first thing to do in order to relieve pressure from the primary datastore(s). A simple client-server design fits the bill.

The server's application logic is replicated across multiple compute instances.
Scaling
Auto-scaling can easily be achieved in any Cloud Platform.
Final Words
The measurement of latency throughout this post has been from producer to consumer within a datacenter. Special consideration needs to be made for websites regarding the distribution of their customers around the world. Using CDNs to distribute static content from datacenters around the world is a typical first step to solving the problem of geographic latency. Further steps can be taken, and they're touched on in the post about High Level vs Low Level.